


AIgeist 26 │La stagione delle 🤏🏾mini-AI è adesso │Da OpenAI a Mistral, tempo di annunci│Perché piccolo è meglio (e spesso free)│I modelli più gettonati │Sondaggio: siamo pronti?
Benvenuti in AIgeist, la newsletter settimanale che parla semplicemente di AI.
AIgeist si prende una vacanza. Ci rileggiamo il 21 Agosto. A presto!
Le altre nostre newsletter: Finambolic (martedì), Xerotonina (giovedì) sono tutte da leggere, nell’attesa :-)
Il tema è - La stagione delle mini-AI è adesso
Clem (Clement) Delangue viene da La Bassée, un paese di 6mila abitanti “su al Nord” della Francia, e forse per questo è uno dei più grandi sostenitori e inventori di “piccoli” modelli AI. Oggi è il CEO di HuggingFace, la più grande community di esperti di AI al mondo fondata con due amici nel 2016, e vive in Florida. La piattaforma/repository contiene moltissimi modelli linguistici, materiale di libera distribuzione e conoscenza a fiumi. Usiamo allora Clem per rispondere alla domanda che ci poniamo in questa newsletter: perché piccoli modelli linguistici invece dei giganti come ChatGPT 4o o Gemini?
Ecco la sua risposta, pubblicata 9 mesi fa su Linkedin (traduzione AIgeist):
Modelli più piccoli, più economici, più veloci e personalizzati copriranno il 99% dei casi d'uso
Esempio: Non hai bisogno di una costosa auto di Formula 1 per andare al lavoro ogni giorno, e non hai bisogno che un chatbot per la gestione dei clienti di una banca ti dica il significato della vita! I modelli ridotti sono sufficienti per la maggior parte delle applicazioni quotidiane, offrendo soluzioni pratiche e specifiche senza i costi e la complessità associati ai modelli di grandi dimensioni.
Tutte le aziende alla fine vorranno sviluppare l'AI internamente basandosi su AI open-source
Esempio: Tutte le aziende alla fine vorranno sviluppare l'AI internamente basandosi su AI open-source invece di esternalizzare a terze parti tramite API. Così come non esternalizzi il codice sorgente o non condividi la stessa base di codice con i tuoi concorrenti, non vorrai esternalizzare lo sviluppo della tua AI o utilizzare gli stessi modelli dei tuoi concorrenti. L'AI è un componente fondamentale per costruire tecnologie, e le aziende preferiranno avere il controllo completo sui loro modelli di intelligenza artificiale per garantirne l'unicità e l'adeguatezza alle proprie esigenze specifiche.
Efficienza Energetica: Con le crescenti preoccupazioni sull'impatto ambientale dei grandi modelli di AI, i SLL offrono un'alternativa più sostenibile consumando meno energia durante l'addestramento e l'inferenza.
Buonsenso o vera rivoluzione? Intanto tutti i grandi gruppi dietro l’innovazione AI hanno recentemente lanciato i propri mini-modelli, spesso in modalità open source
Ma completiamo l’introduzione, prima di passare alla descrizione dei principali modelli “mini” e soprattutto agli ultimissimi annunci (ben tre in una settimana e tutti di grandi nomi) facendoci aiutare dallo stesso ChatGPT a spiegare cosa distingue un SLL (Small Language Model) da un LLM (Large Language Model) come Chat GPT4o:
1. Numero di Parametri:
Modelli di Linguaggio Ridotti (SLL): Hanno meno parametri, spesso nell'ordine di milioni o pochi miliardi. I parametri sono i blocchi costitutivi del modello che lo aiutano a comprendere e generare testo. Meno parametri significano che il modello è meno complesso e richiede meno memoria.
Modelli di Linguaggio Grandi (LLM): Possono avere centinaia di miliardi di parametri, rendendoli molto più grandi e intensivi dal punto di vista computazionale.
2. Risorse Computazionali:
SLL: Richiedono meno potenza computazionale per l'addestramento e l'esecuzione. Possono operare in modo efficiente su dispositivi con risorse limitate, come smartphone e dispositivi edge.
LLM: Necessitano di risorse computazionali sostanziali, spesso richiedendo hardware specializzato come GPU o TPU e grandi data center per funzionare efficacemente.
3. Dati di Addestramento:
SLL: Sono addestrati su set di dati più piccoli e più curati per ridurre il carico computazionale e concentrarsi sull'efficienza.
LLM: Sono addestrati su enormi quantità di dati diversificati, che li aiutano a comprendere una vasta gamma di argomenti ma aumentano anche le loro dimensioni e complessità.
4. Velocità ed Efficienza:
SLL: Forniscono risposte più rapide e a bassa latenza, essenziali per applicazioni in tempo reale come chatbot e app mobili.
LLM: Sebbene potenti, possono essere più lenti a causa delle loro dimensioni, rendendoli meno adatti per applicazioni che richiedono risposte immediate.
5. Implementazione e Manutenzione:
SLL: Più facili ed economici da implementare e mantenere grazie alle loro dimensioni ridotte e minori requisiti di risorse.
LLM: Più costosi da implementare e mantenere a causa della necessità di infrastrutture ad alte prestazioni e continua potenza computazionale.
6. Casi d'Uso:
SLL: Adatti per compiti specifici dove sono necessarie alta efficienza e velocità, come la previsione del testo in tempo reale, assistenti personali e applicazioni AI embedded.
LLM: Utilizzati per compiti più complessi che richiedono una comprensione approfondita e analisi contestuale, come la generazione di contenuti su larga scala, risposte a domande complesse e analisi dettagliate dei dati.
Insomma sono più piccoli, verticali, girano nella memoria di un PC o di un telefonino e possono essere adattati più facilmente a scopi singoli e in ambienti di dati protetti e privati. Ma come performano, in termini assoluti?
Pare non facciano grande differenza rispetto ai modelli “larghi” che usavamo anche pochi mesi fa, la tabella sotto lo dimostra:
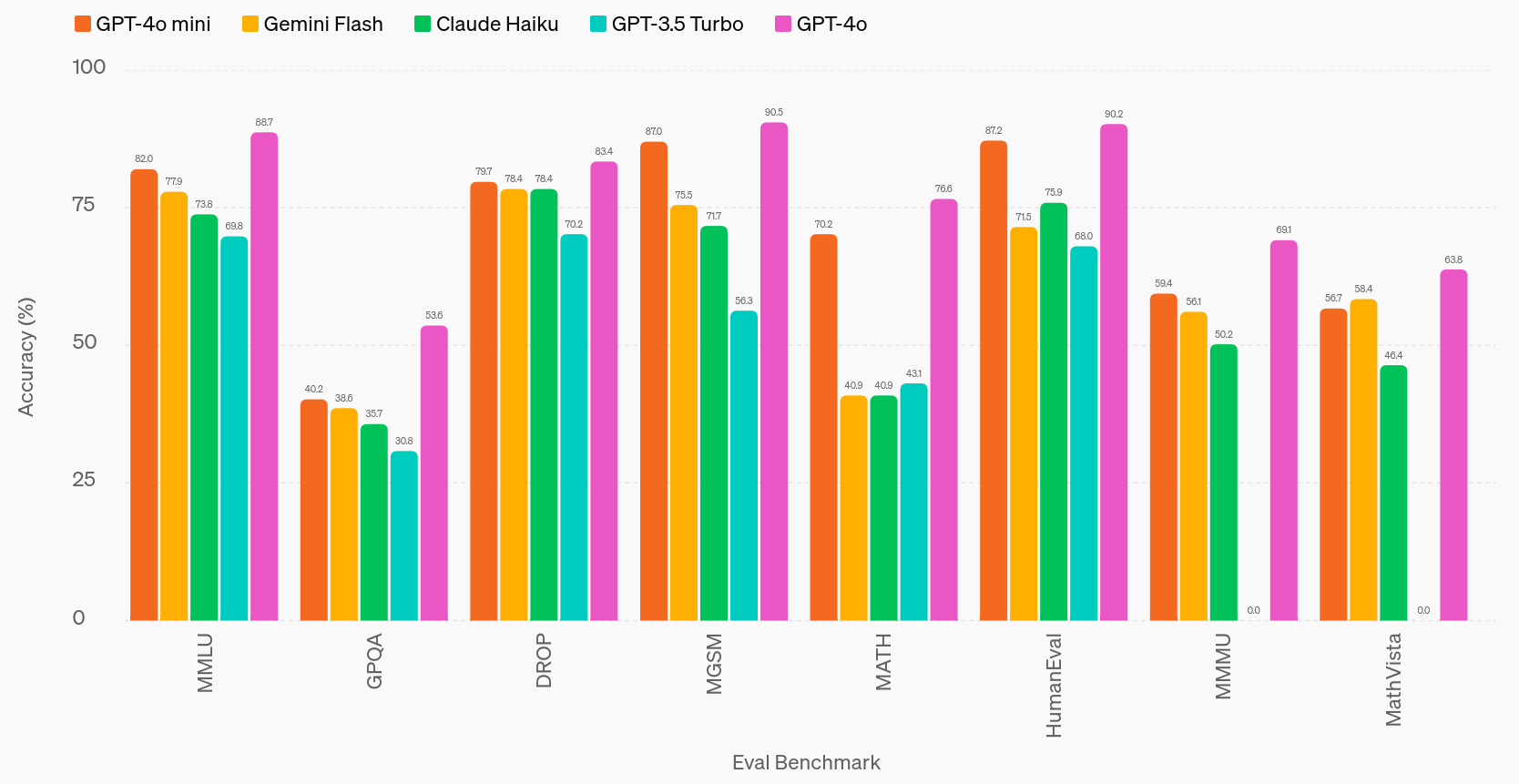
Infine come abbiamo già anticipato gran parte di questi modelli si colloca sotto qualche forma di licenza open source, permettendo ampie adozioni da parte di istituzioni e aziende, pur rispettando la qualità del codice e la distribuzione della conoscenza. Questo non vale per i modelli premium primari o “larghi” che sono vere e proprie corazzate di copyright, licenze, diritti d’autore e protezione dall’uso “free”.
Ora vediamo gli ultimissimi annunci:
Tre protagonisti principali dell'intelligenza artificiale hanno presentato questa settimana modelli di linguaggio compatti, segnando un importante cambiamento nel settore dell'IA. Hugging Face, Nvidia in collaborazione con Mistral AI e OpenAI hanno ciascuno rilasciato piccoli modelli di linguaggio (SLM).
Eccoli:
Mistral NeMo: annunciato il 18 Luglio 2024, è stato realizzato in collaborazione con la casa di chip Nvidia. Il suo focus è sulle lingue principali (non gestisce immagini e video), sulle quali ha realizzato secondo la casa francese una grande ottimizzazione di funzionamento. Va bene quindi per riassumere documenti, scrivere testi o realizzare chatbot interattivi. La modalità di distribuzione è la licenza Apache 2.0, per agevolarne sempre secondo Mistral l’adozione da parte di enti di ricerca e aziende.
OpenAI GPT-4o mini: anch’esso annunciato il 18 Luglio - che coincidenza… - è secondo la casa californiana il 60% meno costoso rispetto ai modelli principali, contiene dati “fermi” all’Ottobre 2023 e “per ora” non supporta audio e video. Eredita dai modelli principali i “guardrail” di sicurezza che rimuovono hate speech, contenuti inadatti eccetera dai sistemi di training.
Hugging Face SmolLM: questo modello è disponibile in 3 grandezze (135M, 360M, e 1.7B di parametri) e dichiara il corpus su cui è stato allenato (vedi al link, dove un blog post molto dettagliato spiega come è stato costruito il sistema). Possono agevolmente girare su comuni smartphone
Microsoft Phi-3: il sito Microsoft che descrive questo modello è davvero completo e spiega con dovizia di particolari casi d’uso e caratteristiche dei piccoli modelli in generale. Anche Phi esiste in varie versioni, 4 per l’esattezza, ognuna specializzata in cose specifiche come il coding in Python, la generazione di testi eccetera. I dati di training sono fermi a Ottobre 2023. Il pagamento avviene dentro la piattaforma cloud Azure della azienda di Redmond.
Google Gemma 2: qui invece siamo in ambito Google Cloud, e Gemma la versione “mini” del popolare Gemini lanciata tra Febbraio e Giugno 2024 con questo estensivo paper (in pdf). L’accesso è gratuito tramite dei token di prova da “spendere” nel sistema Google Cloud. C’è anche la versione Paligemma che si occupa di riconoscimento di immagini e creazione automatica di didascalie.
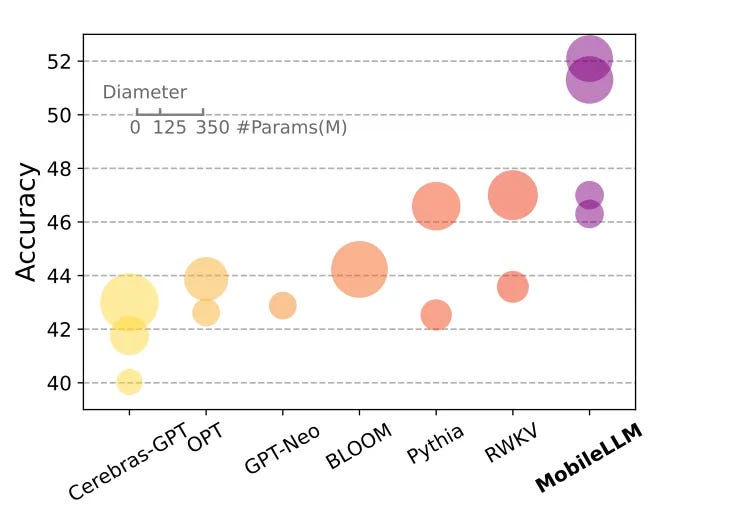
Meta MobileLLM (in sviluppo): il nome racchiude un po’ tutta l’idea di questo progetto di Meta, per ora sintetizzato in un paper (in Pdf) molto esteso. Meta non è la prima azienda che prova ad attaccare il mercato dell’”on device”, e l’articolo che linkiamo sopra nomina e confronta anche i potenziali concorrenti come GPT-neo o BLOOM-ai (sotto in immagine il confronto diretto).
Alibaba Cloud Qwen2: secondo l’azienda cinese questo modello supera altri sistemi open source in almeno 15 parametri. Funziona in 27 lingue, compreso l’italiano e, sempre secondo quanto si dichiara a Pechino, mantiene alti requisiti di sicurezza.

Mobile LLM vs altri modelli per smartphone - Fonte
Sondaggio della settimana
Arrivederci ad Agosto!