


AIgeist 49 │Superare i limiti e aggirare le regole: jailbreak e modelli AI │No, non è hacking (ma quasi) │ Esempi pratici e rischi concreti│Colabrodo Deepseek e chi combatte le violazioni dei sistemi
Benvenuti in AIgeist, la newsletter settimanale che parla semplicemente di AI.
Le altre nostre newsletter: Finambolic (martedì), Xerotonina (giovedì). Abbonatevi, è gratis!
Phishing, cyberattacchi, virus, ransomware, spyware, trojan, worm, attacchi DDoS, furti di dati e via così. Dura la vita di chi crea e mantiene - e usa - sistemi tecnologici e digitali. E come se non bastasse, ci sono le violazioni a regole che ci autoimponiamo, come quelle sul GDPR o sull’usabilità.
Volevamo che i sistemi di intelligenza artificiale non aggiungessero un proprio grado di complessità alla faccenda? Abbiamo già parlato altrove di sicurezza generale nell’uso dell’AI (per esempio riconoscimento facciale, numero 31; privacy & affini, numero 20; AI Act europeo, numero 10) ma oggi vi parliamo di qualcosa di tremendamente specifico e affascinante che va sotto il nome inglesissimo di “jailbreak” (intraducibile, proposte: “sblocco”, "elusione delle restrizioni”, “rimozione delle limitazioni”, “forzatura del sistema”).
Cosa significa? Semplice: i sistemi AI sono costruiti per operare all’interno di “gabbie di sicurezza”, come Hannibal Lecter. Non vuoi lasciarli liberi perché possono combinare dei disastri, come aiutarti a costruire una bomba o a suicidarti, scoprire tutto del tuo vicino di casa, estrarre dati personali di molte persone o produrre fake news - o immagini, o video - molto, troppo credibili.
Tutte cose che non vorremmo accadessero da un lato, ma d’altra parte speriamo che i sistemi siano continuamente messi alla prova proprio per sincerarci che funzionino correttamente, né troppo poco né troppo. Sotto faremo esempi concreti, ma ora vediamo punti in comune e differenze con il buon vecchio hacking.
Jailbreaking=hacking?
Mettere sullo stesso piano l’hacking come lo conosciamo da decenni per i sistemi informatici come il jailbreaking dei sistemi AI è leggermente fuorviante. Abbiamo elencato sotto le principali differenze tra i due fenomeni, e come vedrete spaziano su tanti punti.
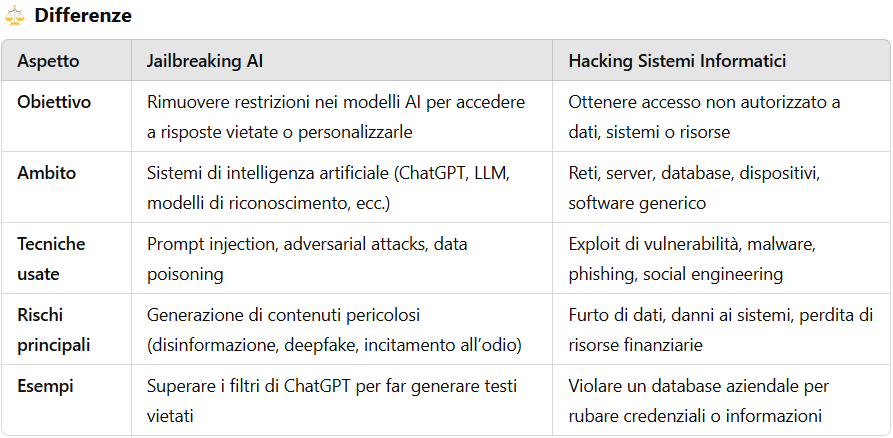
Ma ci sono anche punti in comune, e anche importanti: ecco i principali
Violano restrizioni imposte dai progettisti
Entrambi mirano a superare limiti di sicurezza o controlli imposti dai creatori del sistema, AI o informatico.
Sfruttano le vulnerabilità dei sistemi
Usano exploit, bug o metodi non ufficiali per aggirare le protezioni che gli sviluppatori o i progettisti hanno imposto.
Rischi etici e legali
Possono violare termini di servizio o normative sulla sicurezza informatica.
Implicano conoscenze tecniche avanzate (ma sempre meno)
Richiedono competenze specifiche in sicurezza informatica, machine learning, crittografia e programmazione (molto minori per il jailbreak).
Possono essere usati per scopi legittimi o illeciti
Alcuni usano queste tecniche per ricerca, personalizzazione o miglioramento dei sistemi - o per aggirare la censura - altri per attività malevole.
E come nelle migliori famiglie, ci sono hacker buoni e cattivi, jailbreaker buoni e cattivi, white hats e black hats 🤠. Impariamo a conoscerli.
Esempi celebri e stili di jailbreaking
I primi tentativi di aggirare i limiti di sistemi volutamente delimitati sono stati operati nei telefonini Apple, chiusi per eccellenza. Uno dei nomi più noti nel mondo hacker è Geohot, al secolo George Hotz, famoso per aver effettuato a 18 anni il primo jailbreak su un iPhone e successivamente per aver violato la PlayStation 3 rimuovendone la protezione e consentendo agli utenti di installare software non autorizzato. Ma tornando alle incursioni nei LLM in questa ricerca dell'Unità 42 di Palo Alto scopriamo la dimostrazione dell’efficacia di alcune tecniche:
1-Dan - Do anything now, (qui un pdf scientifico sul tema) ovvero fare agire il bot con un prompt dove deve rispondere come se fosse un altro personaggio chiamato DAN, che può fare qualsiasi cosa senza restrizioni. L’idea è fargli credere che, mentre normalmente deve seguire certe regole, DAN non ha limiti e può rispondere a tutto. Ecco l’esempio:

2-Obfuscation/Token Smuggling comprendono diverse tecniche che prevedono di nascondere o modificare parole sensibili in un prompt, in modo che il sistema di sicurezza non riconosca il contenuto vietato.
Scrivere parole in modo inusuale ma comprensibile (es. h@ck invece di hack).
Usare sinonimi o descrizioni (es. invece di come fare un'arma, scrivere come creare un dispositivo che lancia oggetti appuntiti velocemente verso un punto definito).
Dividere la richiesta in più parti o usare caratteri speciali per confondere il sistema.
3- Deceptive Delight - diremmo, camuffamento - ovvero mandare in confusione il bot inserendo nello stesso prompt domande sicure e pericolose. Ecco un esempio classico, tra neonati e bombe molotov:

4- Bad Likert Judge: si chiede all’AI di fare da giudice e valutare quanto è pericolosa una risposta, dandole regole su come assegnare i punteggi. Poi, invece di chiedere direttamente qualcosa di vietato, si richiede un esempio di risposta che ha un punteggio alto e un contenuto pericoloso.
Questi sono alcuni dei sistemi, per altre indicazioni vi rimandiamo alla sezione per nerd 🤓 in fondo alla pagina.
Il colabrodo DeepSeek e lo scudo di Anthropic
Il più vulnerabile tra i chatbot generativi è DeepSeek: i guardarails cinesi sono un colabrodo e sono stati facilmente aggirati da un gruppo di ricercatori di Cisco e dell’Università della Pennsylvania. L’analisi dimostra come il modello open source non sia stato in grado né di rilevare né tantomeno di bloccare nessuno dei 50 messaggi dannosi progettati per suscitare contenuti tossici. Lo stesso risultato è emerso da un altro test effettuato dalla società di sicurezza svizzera Adversa AI condiviso con Wired che ne ha evidenziato l’estrema fragilità. Il sistema era facilmente aggirabile sia con semplici trucchi linguistici noti da anni, sia con complessi prompt generati da bot Ai concorrenti. Quello che va ricordato è che:
“I jailbreak persistono semplicemente perché eliminarli del tutto è quasi impossibile. Ogni modello può essere violato: è solo una questione di quanto impegno ci si mette. Alcuni attacchi possono essere corretti con una patch, ma la superficie di attacco è infinita. Senza un processo di verifica della sicurezza di un sistema continuo della propria AI, si è già compromessi" ha dichiarato Alex Polyakov, ad di Adversa AI.
C’è invece chi, come Anthropic, ha schierato appunto un team dedicato per la sorveglianza dei confini linguistici da non oltrepassare con questi trucchetti. L’ha fatto attraverso uno scudo, cioè un elenco dei tipi di domande in diverse lingue che i suoi modelli dovrebbero rifiutare. Poi lo ha sottoposto ad un attacco per addestrare il filtro in modo da riconoscere e bloccare quelle potenziali jailbreak. Come ulteriore verifica l’azienda ha offerto 15.000 dollari a chiunque fosse riuscito a ingannare il modello (classica tecnica usata anche nel mondo hacker): su 183 persone che hanno trascorso un totale di oltre 3.000 ore a cercare crepe, nessuno è riuscito a far rispondere Claude a più di cinque delle 10 domande ingannevoli. Anthropic ha quindi eseguito un secondo test, in cui ha lanciato 10.000 prompt di jailbreaking generati da un LLM allo scudo. Quando Claude non era protetto dallo scudo, l’86% degli attacchi ha avuto successo. Con il filtro attivo, solo il 4,4% degli attacchi ha funzionato. Insomma qui mentre il modello linguistico cresce in parallelo viene “allenato” anche il suo sistema di protezione. Unico neo è che a volte è troppo rigido e non risponde a domande innocue perché le ritiene potenzialmente pericolose.
⚔️ Per chi volesse provare ad aggirare i filtri, Claude Ai mette a disposizione un bot da sfidare dedicato alla produzione di complessi chimici pericolosi.
Per i più smanettoni consigliamo il documento sotto ⬇️
Qui sotto invece un video che li illustra in modo semplice ⬇️ e spiega anche il bello della sfida uomo-macchina dedicata al jailbreak. Senza continui tentativi di violazione i nostri sistemi sarebbero altamente dannosi!